TL;DR – There is this misconception that top Software Developers are appreciated due to their technical coding skills, for example how fast they can code a solution to a problem. While coding is very important, the real strength of top developers comes from understanding the domain of the problem they are solving.
The code should be the last thing on your mind
Have you ever interviewed a developer that when asked to solve a problem, they immediately approached the whiteboard? No matter how vague your question might be (purposely or not) they take their marker-caps off and start coding.
Unless the question is a well known algorithmic problem that you can learn by heart, there is only 1 possible outcome to this – you will stumble on every step of the way and you will probably NOT solve the problem correctly. And even if you do solve it correctly, it will take you much longer than expected.
This should be a huge red flag for every hiring manager or an interviewer.
So, my question is, why so many developers think that they are evaluated solely by their technical coding skills??
We learn the wrong things from others
We all try to learn from others and we all know that learning from other great professionals is the best way to advance your personal growth and your career. I think Louis Armstrong said it best: “If you are not the worst trumpeter in the band, you should find a new band”. And so we do. We change teams, we change companies, we alway try to find new challenges and top engineers to learn from.
My question is: are we learning the right things from those around us?
Lets take Jimmy as an example. Jimmy is a software engineer in your team. She is highly appreciated by her managers and peers. She gets her work done fast and her work is usually at top quality. She is what some may call a 10x-er. We want to be like her. We want to be like Jimmy.
When we look at her, what do we see? We mostly see her coding, and so we think to ourselves, hey, look how fast she is! She is so fast at solving this problem! I should try solving my problems as fast as she does! She is so talented and smart! I wanna be just like her!
But eventually somehow this doesn’t work. You get frustrated. You think that you are simply not that smart and you just don’t have what it takes to be at the top. You loose faith. You try coding your problems faster, but you keep stumbling and falling over and over again.
What you don’t usually see, is that there is another, slightly hidden variable with Jimmy. Turns out she only start coding when she understands the domain and the problem. If she doesn’t – she asks questions, she learns, she questions. She takes her time to understand the domain of the problem. She is looking beyond her code. She knows that the code is just a mean, not the solution.
So, in conclusion, Jimmy is not paid for coding. She is paid for thinking, for understanding the problem, for designing the business solution and finally, only at the end, applying he coding skills to implement the business solution.
What can I personally do better (my personal resolution)
The next time I am assigned to solve a problem, I WILL ask myself the following questions, and unless they are all answered with a YES – I will not start coding:
Do I understand what is the problem I am actually trying to solve?
Is the problem really a problem?
Do I understand the current state of things?
Can I explain the problem to others in a very clear way?
Sometimes the answers to these questions will make you understand that there is no problem, or maybe there are much simpler solutions to the problem at hand. In any way, you will most probably find the best solution to your problem.
Anyway, lets all be just a little bit more like Jimmy.
TL;DR – The development environment of a Go developer is very different from that of C#. All Go source code lives in a single workspace, there is no GAC and your machine Environment Variables play a main role in locating code, tools and binaries.
*I strongly recommend using the official page for installation and configuration.
GOPATH vs. GOROOT vs. GOBIN
To set-up the Go environment, all we need to do is to configure 3 environment variable:
GOROOT – is the directory where your Go installation, docs, tools and Go standard library lives.
GOPATH – is where you work, and where all your sources (and the sources you pull down) live. It is your workspace.
GOBIN – is where your executables will be placed after you install a go program form source by running ‘go install’.
Assuming you are a windows developer, you should remember that as opposed to .NET, there is nothing like the GAC or the use of the windows registry for dependencies resolution. Your dependencies get resolved via those 2 environment variables.
Also important to remember that while in c# we can dynamically load a .dll assembly at runtime, in Go there is only 1 compiled assembly with all the dependencies compiled into it from source.
GOROOT
When you install the Go MSI on windows, the default location will be set to c:\go.
GOPATH
Now that we can find our workspace on disk, the workspace itself must contain 3 directories as follows:
src – that is where your source and dependencies live
bin – that is the location of installed executables
pkg – is where compiled files live
GOBIN
I personally set-up my bin folder like this: %GOPATH%\bin. That way my go tools and installed executables are all placed in one directory that is easy to find.
After installing Go and configuring the mentioned environment variables, you are all set to proceed to your first helloworld example.
TL;DR – In this series of posts I am exploring the Go (Golang) language from a C# native speaker’s perspective (or through one’s glasses). This introductory episode is more about the philosophy, history and general geekout over Go. You won’t see any code today. This series is sort of a personal library about my adventures with the language.
[The terms Go and Golang are interchangeable. If you want to know why there are 2 names for a programming language, try googling something with the keyword ‘go’]
Lets start with a riddle: what does UTF-8 encoding and the Go programming language have in common? Place your answers in the comments, and you may win a talking gopher-pet 🙂
History and philosophy of the Go language
I love learning and playing with new technologies, learning new programming paradigms and techniques. Lately I’ve been programming in Go, which is a relatively new programming language from Google. Go is young (2009), fun and very opinionated. After reading the book titled “The Go Programming Language”, tons of blog posts and all pluralsight videos, I fell in love.
I am a failing philosopher at heart. When I want to understand something, I need to understand the philosophy behind it. So what is the philosophy of Go and why it became so popular so quickly? Do we really need it? Is anyone actually writing production code with it?
Moore’s law and the rise of concurrent programming:
After decades of making processor chips faster, the reign of Moor is weakening – the advancements in processor’s performance is slowing down. Naturally, the software industry took a turn too: instead of concentrating on faster and faster processing of a single task, we are investing in concurrent processing of multiple tasks, maybe even on multiple processors. Concurrency became a common tool to boost performance and processing time of programs.
What is also natural, is that more and more tools have emerged to simplify concurrent programming. Lets face it, concurrency is hard. Threads are hard. Synchronization is hard.
Think about it, humans don’t get statistical data, so they invented pie charts and graphs. Humans also don’t get concurrent programming, that is where Google comes in with Go.
CSP and Actor model (feel free to skip to the practical parts below):
Concurrent execution and communication models for computers were researched years ago, the theories are not new. Some of the more popular academic papers were published in the 70’s and today are considered groundbreaking. 2 of the most notable papers are on the Actor model [1973] and the CSP model [1978].
In the 21st century, with the rise of parallel computing and demand for concurrent programming, the classic and mainly academic papers became really popular and found their way to the mainstream of the practical tech world. Some of the manifestations of this are the frameworks and languages that emerged or simply became very popular in the past 16 years that are based on those theories. Here is a short list:
So as we can see, the rise of Golang (and others) is just a natural turn of events. Go is inspired by the CSP paper mentioned above. CSP stands for “Communicating Sequential Processes”, and the original paper described a formal language for concurrent systems patterns and their communication based on message passing techniques.
The practical
So what do we have and maybe more importantly what don’t we have in the language?
Pointers – lets get this out of the way right now, Go has pointers, OK? There, I said it. Most of the people that are looking at my code, get terrified saying this looks like the C language, but the pointers in Go are very different than the ones we know from C or C++. It is not an easy task to shoot yourself in the foot with Go’s pointers. For example there is no such thing as pointer arithmetics, and returning a pointer from a function that points to a local function variable will not get you to those dark places where NullPointerExceptions live.
Garbage collected – although there are pointers in Go, the programmer is not responsible for memory management of his programs. Go developers don’t have to use manual memory allocations and cleanup.
Compiled to machine code – Go runs as a single binary that contains the machine code. There is no Go VM or anything like the CLR or JVM, and hence no JIT complication at runtime. This makes Go code extremely fast and performant.
Concurrent – Go has concurrency built in to the language. This is perhaps the strongest point to be made about the language. If you accept how Go deals with concurrency, your life will improve dramatically. I will go into more details in future posts to show you in more detail how simplified the concurrency reasoning is in Go.
Small and Opinionated – the Go language is extremely small. The number of language features and keywords is kept to a minimum. The creators of Go intentionally deny any propositions or requests for new features. There is only one way to do things in Go – and it is the Go way. No more holly wars over curly braces and loop structures. The biggest benefit of this approach is that the entry barrier for the Go language is very low. Reading someone else’s code is easy, and if you are new to the language, you will become productive in a relatively short amount of time. Go creators believe that less is more, and they have very compelling arguments for that.
No OOP – Go is not an object oriented language. There are no classes and there is no such thing as inheritance. However it is a statically typed language. The building blocks of a program are packages containing files, types, functions and methods. Go also supports interfaces (which I will cover in future episodes), however they are much more flexible than what we are used to with languages like c#.
Bottom line it is very different from C#, but very powerful and interesting. Barrier to entry is very low, and the language is very simple. There is a steadily growing community around the language and more and more software companies build products written mainly in Go. Check out the list of open source projects developed with Go on the language’s wiki page.
TL;DR – You don’t really need IIS to perform full automation testing to your web project. Today I want to show you how I am testing my ASP.NET WebApi services without IIS by using OWIN/Katana.
After I was done with the main development (including unit-testing) I started thinking about how to go around the automation testing story.
As I consulted some of my developer friends (and Google), I was very surprised that the recurring theme was that they either don’t do full automation testing or they do, but only partially. Why? Most of them blamed the issue of hosting – in other words they needed IIS to host their WebApi service.
At this point I asked myself, do I really need to spin-up the IIS beast? Or can I somehow overcome that dependency and self-host my service? As it turns out, there is a pretty simple way to self-host your service in-process, without the need of any external web servers.
Enters: OWIN (Katana)
So what is this OWIN thing? Here is a short description from owin.org:
This basically means that you can build your OWIN implementation and use it to host your web project yourself, without the need for a web server (like IIS). The good new is, Microsoft already implemented OWIN in a project called Katana.
This meant really great news for my automation testing needs. I decided to take it for a ride, and so I wrapped the whole thing in a UnitTesting project and the rest is history.
Note that I also incorporated Ninject for Dependency Injection in the source code, that way you can also see how to provide dependencies for your api controllers during testing.
You can find a working template on my GitHub account. Simply clone the repository and run the unit test.
TL;DR – I am using SSDT for developing a new SQL Server Database, and it changed my life. Everything is version-controlled, scripts are being generated automatically and DB deployment is finally a piece of cake. And SO much more. Using SSDT allows rapid iterations, while changing my Database as easy as my code. I finally have a full-stack solution where i can develop all my layers in one place, one flow and one source.
(The ideas and practices are general, but the practical tools are from the Microsoft stack: Visual Studio and SQL Server).
I was recently tasked with extending a legacy SQL Server database, and build a new Web Service on top of it. While planning my tasks for the upcoming sprint, I asked myself the usual questions:
How can I easily track my changes made to my DB schema?
How can I minimize human error when developing scripts for various DB changes?
How can I easily deploy my new DB?
How can I quickly iterate over and over again with rapid changes to the schema and stored procedures?
DB as code
All those points above got me thinking, why on earth won’t we love our Databases like we love our code? I mean, it is almost unacceptable to NOT use some kind of version-control for your code-base or NOT use some kind of an IDE with intellisense and code completion. Moreover, it is becoming a global standard for teams to employ CI and CD practices (Continuous Integration and Continuous Deployment respectively).
So how come it is almost 2017, and we are still writing SQL scripts in notepads and deploy it manually to our DB servers? Seriously… Stop this cave-man madness…
Enter SSDT
SSDT stands for SQL Server Data Tools. It is Microsoft’s shot at solving ALL those issues I mentioned above and much much more.
Now that we got that out of the way, let’s dive deeper. SSDT is yet another project in your Visual Studio solution that will let you easily manage your entire SQL server locally and deploy the whole thing with 1 click. Ah, yes, for every change that you make in the schema or any other object in your Database project, SSDT will generate the appropriate scripts that will replay the appropriate changes on your server.
This seemed amazing from the get-go, however it’s power turned to be much greater. A game changer in our dev community, no less.
Projectify your Database
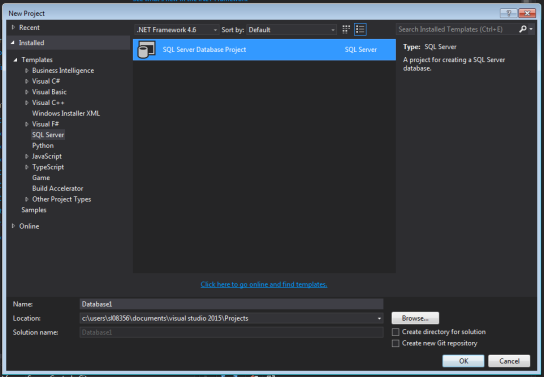
It is Monday morning, you had your morning coffee, you read this blog-post and decided it is a good time for some cool and quick experiment. To take SSDT for a ride, create a Database project in Visual Studio and see what happens. You will be amazed.
Create new project:
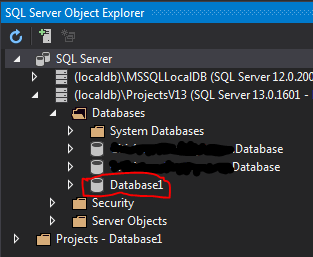
Now the important thing to notice here, is that along with the DB project in the Solution Explorer, there is a database instance that was automatically generated for you, and you can see it in the ‘SQL Server Object Explorer’.
Do you see what is going on here? You have a local Database in 3 seconds! That is all you need for your development.
Now you can add different Database objects (like tables, stored procedures etc…) and publish your project to update your local database. I hope you realize how amazing this is.
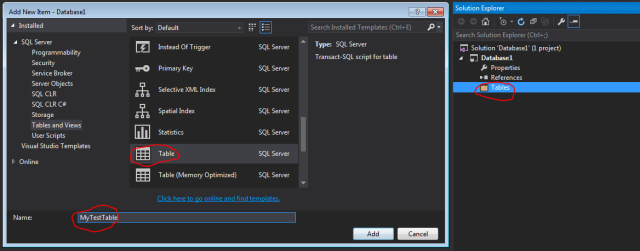
Lets add a table to our DB project:
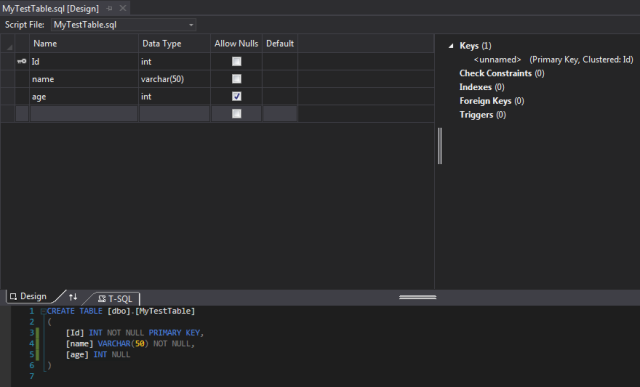
Note that a beautiful designer opens up, and anything you change in the UI, will generate an appropriate SQL script that will be replayed later on your Database schema.
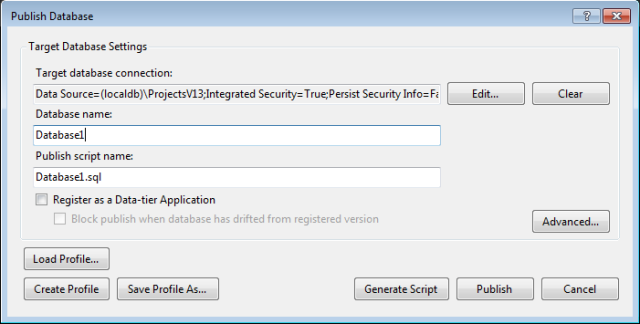
Now how do you update your local Database instance? Easy peasy – right click on the project node, and choose publish. You will get this window, so just choose your local Database and press ‘Publish’:
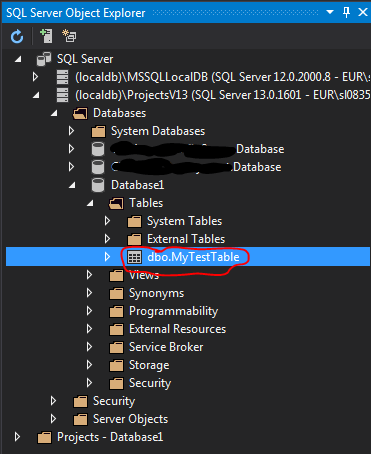
After 3 seconds, you should refresh your SQL Server Object Explorer and wallah, our DB is updated, and we see that we now are proud owners of a new table:
I am so excited, I can’t stress this enough! You now have an updated Database instance on your dev machine, local DB that you can program against and update the schema on the fly with friendly designers.
There are many (MANY!) other options and configurations like live Database debugging, advanced DB configurations, visual designers etc… Almost anything you can do manually on your server, you can now configure with SSDT and the appropriate scripts will be generated in real-time, leaving you happy and filled with free time for the important things.
I will probably post more on SSDT in the future, but for now you can extend your knowledge with the following resources:
TL;DR – There is a server. It is not a “my-on-premises-Linux-box” kind of server, but there is one at the end. Perhaps it is just not yours and looks and feels a little bit different from the developer’s perspective.
The Buzz-Word
What would you answer if I asked you what is our industry best at? Well, I personally don’t know what we are best at, but we are definitely very good at creating buzzwords. The recipe for a perfect one would be to take some terms we all know and love, tweak them a little bit and use it to describe a completely different thing.
The new buzz-words in the industry today are ‘Serverless Architecture’. We can all imagine something when we hear our colleagues say the word ‘Server’ at the water-cooler. If you are a more traditional Desktop oriented developer, you probably think about a physical server-box that might be sitting in the next room. If you are a Web developer, you might be thinking about a Reqest\Response type of server that is running some server-side technology like ASP.NET or NodeJS.
In any case, when you hear ‘Serverless Architecture’ you probably think about an Architecture that has no Servers. So, are we back to rich client desktop application that only talk to a database? Or maybe the clients will talk between themselves without a server? Perhaps some new peer-to-peer oriented technology?
Well, that’s how you know that the new kid in town is misleading – it means something completely different from what it seems.
The General explanation
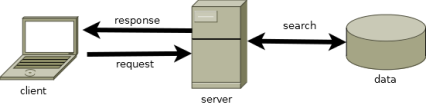
How we generally imagine our architecture:
I am simplifying here in favor of clarity, but a ‘Serverless Architecture’ basically means that the server as YOU know it is gone. The server in general is still there, but it looks and feels a little bit different from the developer’s perspective. It is somewhat of a redefinition of the word Server.
Some may think that this is a natural turn of events. As in everything, we always have opposite forces that pull to other directions, but eventually, after a turmoil, we find an equilibrium in which those forces lay still. In our case in Software Architecture, there are 2 major forces – one that states that the “Server is God” and the other states “Client is God”. As with anything else, non of those forces are “correct” so to speak. The are many good reasons why for so many years the Server ruled the world, and now with the advancement in computing power and client side capabilities, we are shifting quickly in to the Client oriented architectures. In this new world the the server simply provides discrete, stateless functionality for the Client.
In the last 10-15 years we’ve seen the server becoming an external worker, sort of a contractor that provides discrete functionality for the Client. We migrated the business state of our applications from the Server to our Clients, so the server only comes in to play when the Client needs some specific functionality like Persistence, Authentication or heavy-weight calculations. The clear evidence is in the popularity of Microservices these days (another buzz-word, I know). So developers started breaking their monolithic Servers down to little independent pieces where each piece will perform a specific task (or a Service if you will).
Naturally, when one of the forces has its momentum, we are shifted to the extremes. In our case, the extreme is the ‘Serverless Architecture’. We decided that a Service is not a discrete or lightweight enough backend, so what is the next stage of diminishing the backend? The next stage is to break those services into even smaller pieces like functions. Yes, as in a function should become a service with an endpoint. It has an input, it performs a task and maybe emitting some output.
So we started by taking away the state from the servers, they became kind of one-time contractors per specific input. No state. Then, if the servers have no state and they only perform specific functionality, why should they exist as an integral piece of our system? Can’t we just break the functionality to a more granular level and then outsource that functionality to a third party vendor? We can. That is what ‘Serverless Architecture’ means.
BaaS vs. FaaS
Some of the literature out there is calling ‘Serverless Architecture’ different names with a slightly different meaning, but the general idea is the same – you should not write your server logic and maintain a server (or Service if yo wish), rather you can delegate that functionality to 3rd party vendors like Amazon, Microsoft, Google or any other vendor.
BaaS – Backend as a Service. The more popular use of this term would be with a Mobile backdrop, so BaaS becomes MBaaS. You basically develop your mobile application while using services like Firebase for real-time DB, AWS Cognito for Authentication services and so on. This type of ‘Serverless Architecture’ is not new, and many articles have been written around that topic.
FaaS – Functions as a Service. This is the new kid on the block. In this case you can consume server side functions without developing your own server, maintaining its code etc. You deploy business code, and that is the only deployed piece of software that you are responsible for. The rest will be provided for you as a service with endpoints.
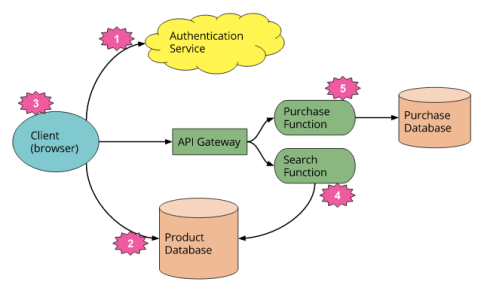
So a Serverless application may look something like this:
There is lots of literature out there regarding this, so i’ll just mention some key points:
If you need a responsive UI, you need to think twice before responding to user events by using FaaS because this will incur additional setup time for the remote function instance. Your function is not a server, it is not sitting around waiting for your request. Using FaaS in this case may present additional latency to your application.
On the other hand, if you are posting messages to a remote and asynchronous message queue, the FaaS provider may set-up a bulk of function instances to process your messages backlog and after it finishes processing the backlog, the function instances will be torn down.
Moreover, think about the DevOps effort that might be saved for you? All you have to do is deploy some kind of package to the server, and instruct the vendor to deploy your new function code. That’s it. The vendor becomes your DevOps guy on demand.
The Biggest Providers
So who are the biggest providers of Serverless functionality? Obviously, the biggest companies are up on the wagon.
I woke up in cold sweat feeling terrified. I knew this day will not be a good one. I couldn’t explain why, I just knew…
09:00:00
I received horrible news this morning – I was assigned with a task to create a windows deployment package (MSI) that will install a server to IIS with a specific file layout and configuration.
At this moment I know nothing about installation packages on Windows, this is going to be an interesting day.
11:00:00
After spending an hour comprehending the horrible news, I figured I need to learn what the hell is a Windows Installer Package (MSI) and how do I go about creating one. I figured i’ll invest couple hours in an online course, so I went through most of this course on pluralsight (god bless the double speed streaming):
I think I am starting to understand what is going on.
Windows has a very old installation mechanism built in to it. To perform an installation, that mechanism needs an MSI package that contains all the information for that particular installation.
Oh, ok, but how do I create such MSI package?
13:34:52
There are several ways to create those MSI packages. The most popular way is to use WIX Toolset (no, not the web site creation wix). WIX stands for Windows Installer XML. So we use WIX to create an MSI that will be used by msiexec.exe to perform the actual installation. Phew, try saying this 20 times in a row.
14:20:48
Found some useful tools:
Orca – this tool enables me to explore the MSI file and see what is actually stored in it. InstEd – this is like Orca but has additional features like MSI package diff between different version of MSI.
14:41:08
Assuming I have an MSI package, to install it with extended logging and debugging info, I should execute this with the following command:
msiexec /i mypackage.msi /L*vx “c:\msilog.txt”
14:48:11
Denial…
16:13:13
Anger…
16:18:14
Acceptance…
17:24:58
Nothing works… I hate Wix and i hate MSI, they ruined my life…
23:41:36
It worked!
It finally worked!
I love Wix!
I love MSI!
00:34:33
Time to unwind, have a cold beer and watch a good TED talk…
TL;DR – Once you try the C# Interactive Window, you will never run another Console App just to try out an API.
You know how they say that if the only tool you have is a hammer, then everything looks like a nail? Well, this is especially true in the software industry. I once witnessed a guy debugging a .NET application with WinDbg just because he is a guru of that tool. At that moment I thought to myself how happy he would be if he only knew the tools available to him with Visual Studio.
Anyway, enough with the jabber, I am here to make you fall in love with the C# interactive window that is available with Visual Studio 2015 update-1.
After finishing the update of you VS, navigate to:
View > Other Windows > C# Interactive
What you should see is a new window that looks like this:
Features, features and features…
Alright, after getting all the boring stuff out of the way, I want to show you what you can do with this. The whole set of features is explained on the official Microsoft GitHub account, so I wont cover everything but give you a taste of the most interesting ways you can use it in your day-to-day development.
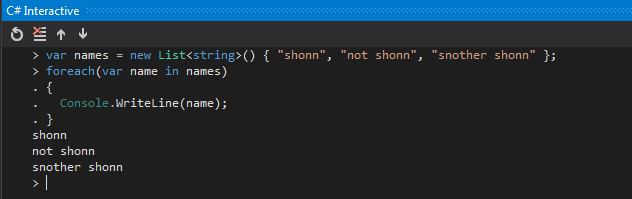
Multi-line support – you can write fully executable script by pressing ‘Shift+Enter’ for a new line, and for actual execution use ‘Ctrl+Enter’ when your script is ready. Consider this snippet:
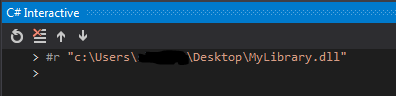
Reference external dlls – you can actually load an external dll to play with it’s APIs by using the #r command like this:
This is seriously a powerful tool!
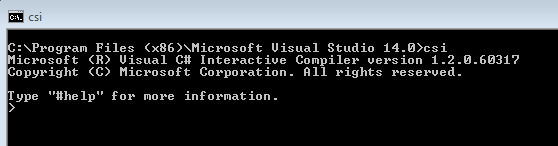
Use interactive outside VS – you can run this environment even outside Visual Studio by simply executing ‘csi’ in you Developer Command Prompt from VS 2015:
Loading saved scripts – you can write a common script and load it in to the execution context by using the #load command. This is super cool when you have a script that is loading an entire environment for you that you can work with with specific APIs.
Execution context – when the window initializes, you can create variables that will live until you type the #reset command. For example try executing the following command, and use the myFile variable in your next commands:var myFile = new FileInfo(@"c:\users\shonn\desktop\myResume.txt");
Navigation – You can navigate executed statements history by using ‘Alt+UpArrow’.
Go ahead and explore more features (believe me there are tons!), it is really awesome!
Feel free to leave a comment if this was helpful 🙂
Shonn Lyga.
Update [29.9.2016] – Due to numerous emails, I wanted to post the exact command I used in my Continuous Integration builds:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
– %BuildToolsPath% is the path to build tools on my build machine.
– %var2% is a placeholder that will be replaced by the file name when debugging. This is the only placeholder that should not be expanded by the build system. It is for the debugger's use only.
– %revision% is the git revision number that should be expanded by the build system to the current revision being built.
– %branchname% should also expand by the build system to the current branch name that is being built.
TL;DR – How I enabled “Source Server” support for an internal Git repository for any Git provider even when authentication to the server is required. I ended up setting up a tiny Web Api service that queries a local clone of a repository on the server and returns a raw file content from a specific revision.
Lets review the big picture and explain the motivation for what I tried to achieve here. If you know what ‘source server’ in Visual Studio is – feel free to skip to ‘The solution‘ section below.
Source Server
How many times you wished you could step into source of some referenced assembly in you project that you don’t own the actual sources for? Well, when you enable the Source Server option in Visual Studio, you basically tell the Debugger to check the .pdb file to try and bring the sources from the location encoded in the .pdb file. Even after using this feature at least a 100 times, it still feels like magic to me when the actual source file suddenly appears in my debugger.
.pdb who?
So now we know that the debugger can fetch the relevant sources for you as long as you have the .pdb file that the debugger can look into to find the location of the sources on the internet. But what are those .pdb files and how can you get them?
Lets say you have a C# library project loaded in visual studio. When you compile the source code with ‘Debug’ configuration, your output would contain your .dll file with the compiled code, and a .pdb file that will contain information for debugging your library. (more on .pdb files HERE)
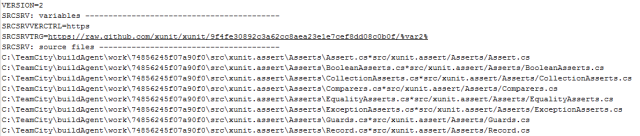
If you try opening the .pdb file, you will see lots and lots of binary gibberish, but if you scroll to the end of the file, you will see textual content that looks something like this (taken from xunit.assert.pdb):
What you see here, is the info that tells Visual Studio where to get the actual sources for this specific revision in case you want to debug the library and step into their source. Of course you can’t access ‘C:\TeamCity\buildAgent’ on the actual machine the library was built on, so if you look carefully, there is an ‘*’ that separates variables and adds the relative path variable the debugging tools will use to try and fetch the correct source from a publicly accessible location that is specified in the ‘SRCSRVTRG‘ variable.
Ok, so now we know that basically all we need to do is to instrument our.pdb files upon build with the textual information that will assist the debugger to retrieve the right file from the exact revision. The good news is that Microsoft supports such instrumentation of your .pdb files and even provides you with the right scripts to do so. I have no clue why, but those Micrisoft scripts are written in Perl (oh God, do I hate Perl).
You can get all the relevant scripts when installing the Windows SDK. They should reside in a path that looks something like this:
C:\Program Files (x86)\Windows Kits\10\Debuggers\x64\srcsrv
The problem
What we’ve go so far, hopefully, is the understanding of what are symbols and how we can debug sources that we don’t actually own. The problem is, that Microsoft is only supporting couple of version control systems that the debugger can fetch sources from with the help of a .pdb file. In the company I work for, there is a desire to migrate to a Git source control system – Stash\Bitbucket.
One of the reasons we are struggling with the migration is due to lack of support for Source Server over a Git repository. Meaning, if we have a CI system that builds our sources from Stash, the debugger will not be able to fetch the relevant sources shall we want to debug some specific .dll library that we deployed to production.
Even if we find a way to instrument the .pdb file to try and fetch sources from Stash, there are 2 issues that stop our debugging:
Our Stash\Bitbucket Git server needs an SSO authentication to access any repository.
To query the Stash\Bitbucket Git server we need to build a URL with query parameters while the debugger will not fetch anything that contains “?” symbol in the URL (seems like a known issue in the srcsrv.dll).
The solution
I’ll get right to the point – I decided to write an ASP Web Api service that will accept a true REST call (without any query parameters) and will use a server-side clone of the relevant Git repository to fetch the exact revision of a file. By doing so, we solve both problems:
We don’t need any SSO authentication because we are using a local clone of the repository over at the Web Service (which actually makes the solution agnostic as for the Git source control we are using).
We don’t have to create a URL with query parameters anymore, because the Web Api service will accept a clean RESTfull request.
Ok, right about now you should be asking “hey, but how is your service querying the local Git clone on the server? Did you write your own library?”. Of course not, I used a library called libgit2Sharp that helped me query my sources simply like this:
So right now, with some out-of-the-box thinking, we solved the problems we had with getting the relevant revision of a specific file that is stored in a Git repository. While this is solved, we have another problem, how the hell are we going to instrument our .pdb files upon build to make the debugger talk to our Web Api service and load the correct sources in Visual Studio?
Enter GitLink! No more cryptic Perl scripts, just plain ol’ C# that will instrument all your .pdb files that are created when building your projects. I wont get into the nuts-and-bolts on how to use this tool, it is pretty straightforward with good documentation on GitHub, but I will mention couple of things I had to solve myself and recompile the latest GitLink sources with my own changes.
(You can see all my changes in this revision HERE)
Change #1: The GitLink command line is expecting my service to talk via https, so I removed the need for https since my service is running via http.
Change #2: This is an important one, when instrumenting my .pdb files with GitLink, I opted in using powershell for fetching the files from my Web Service. But the original code did not work no matter how hard I tried, the Visual Studio debugger did not want to go and fetch my files. So i fixed the command in GitLink to use this line (you can find it find in source):
Change #3: When instrumenting .pdb files, you can’t use relative file locations in your REST call because of the ‘/’ character. I changed the code to replace each slash with a placeholder like this: {__slash__} so when my Web Service gets a request, it first replaces the placeholders with actual slashes before querying the local Git clone of my repository.
Conclusion
Let me go back to 50k foot view, and draw the full picture here.
When you build your project in Visual Studio in Debug mode, your output will contain your .dll library file and a .pdb file.
After you have your build artifacts, you will use GitLink to instrument your .pdb files so they know how to fetch the relevant sources when you want to debug the code.
After instrumenting you .pdb files, you will deploy them to your Symbol Server and point your Visual Studio configuration to use that Symbol Server.
Next, when you wish to debug the exact same version of your .dll, you will try stepping in to any method in that library while debugging, then the Debugger will go get the relevant .pdb file from your Symbol Server and use it to find info you put in the .pdb that lets the Debugger get your sources.
The debugger will use that information to call your Web Service and fetch the exact revision of your sources files. The debugger will then load that file automatically and you will be able to debug the code.
Last thoughts
Only when writing your own blog posts, you understand how hard it is to explain something like this in a written document. I tried to do my best, but if you still have any questions, don’t hesitate to contact me and I will do my best to help out with the implementation.
TL;DR – Use the ‘Modules’ window do view the assemblies loaded at every point of the application’s lifecycle.
Initially i did not plan to write about this, but after observing a team trying to figure out what assemblies are being loaded in to their app’s process, i thought to share this small tip.
So what do you do when you hit a breakpoint in Visual Studio, and all you want is to check what assemblies are loaded, their version, their physical path etc…?
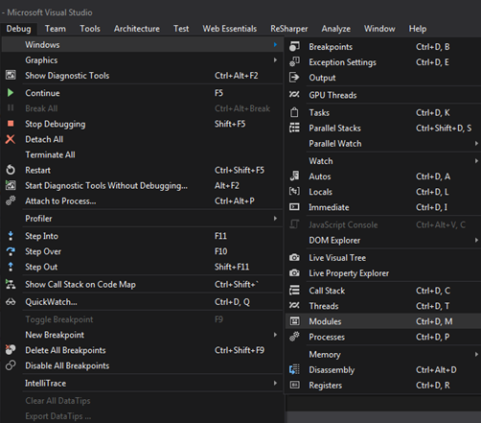
Visual Studio supports this little feature called “Modules” window that can be viewed only when you are in debug mode. To inspect this window, go to
Debug => Windows => Modules (or press Ctrl+D, M)
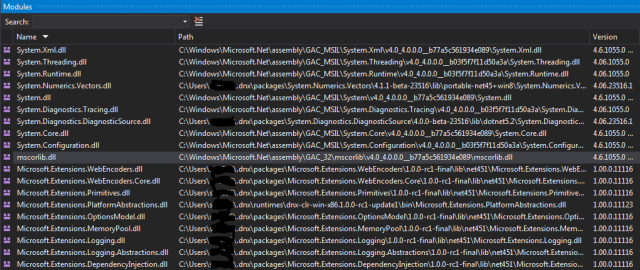
What you should see is a ‘Modules’ window that pops out
If this is the first time you see this window, you will not believe that you’ve been living without it until now. No more wondering when, what and what version is being loaded, just step through your code and see the Modules list updated with the relevant information.









![KeepCalmStudio.com-[Crown]-Keep-Calm-And-Use-Source-Server.png](https://shonnlyga.files.wordpress.com/2016/05/keepcalmstudio-com-crown-keep-calm-and-use-source-server.png?w=295&h=295)